- Using CSS Selectors
- Using Output Filters
- Using External Libraries
CSS Selectors are a query language for selecting HTML elements. When you enable the This code sends a request to ZenRows with the CSS selector This request extracts both the page title and all product names. When a CSS selector matches multiple elements, ZenRows automatically returns them as an array.The response looks like this:The
css_extractor parameter, ZenRows returns structured JSON data instead of raw HTML.Let’s say you want to scrape the title from the ScrapingCourse eCommerce page. The title is contained in an h1 tag.To extract it, send the css_extractor parameter with the value {"title": "h1"}. Make sure the parameter is properly encoded!h1 mapped to the key “title”. ZenRows extracts the content from the first h1 element and returns it as structured JSON data.Extracting Multiple Elements
Now let’s extract multiple elements. Add the product names using the selector.product-name:Extracting attributes
You might need product links to continue scraping individual product details. To extract thehref attribute instead of text content, add @href to your selector.Let’s filter links to only include those starting with /product/:@href syntax tells ZenRows to extract the href attribute value instead of the element’s text content. The [href*='/product/'] part filters links to only include those containing /product/ in their href attribute.This returns:Testing Your Selectors
Before implementing your scraper at scale, test your CSS selectors using our Playground. The Playground shows you the extracted data in real-time and generates code in multiple programming languages for easy integration.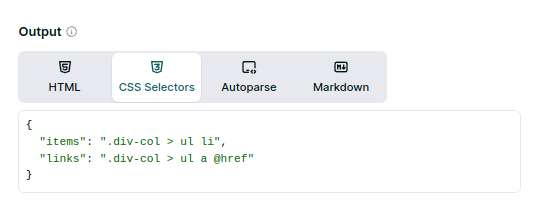
When to use each method
Choose your data extraction method based on your specific needs:- CSS Selectors - Best for custom data extraction when you know exactly what elements you need. Returns clean JSON data with your own key names and structure.
- Output Filters - Ideal for extracting common data types like emails, phone numbers, images, and links. Perfect when you need standard web data without custom parsing.
- External Libraries - Perfect when you need complex parsing logic, custom data transformations, or when integrating with existing parsing workflows.